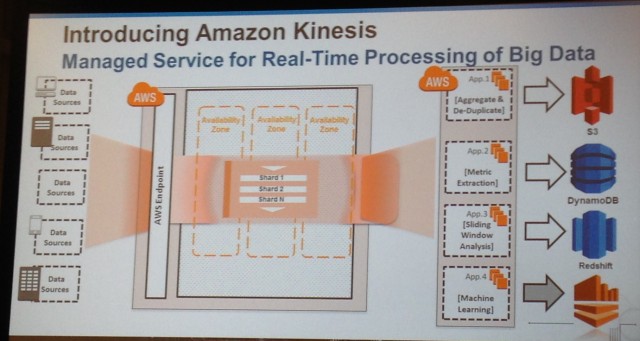
Subiendo al carro "en tiempo real", Amazon ha anunciado hoy Kinesis, un nuevo servicio de procesamiento de flujo que tiene como objetivo ayudar a dar sentido a las fuentes de datos de gran volumen, como de Twitter \ "firehose, \" datos weblog, datos financieros, y cualquier otro los flujos de datos de gran tamaño.
Kinesis se suma al conjunto existente de Amazon de servicios de datos grandes, Mapa notablemente elástica Reducir, una solución alojada Hadoop, corrimiento al rojo, una solución de almacenamiento de datos; DynamoDB, una tienda de NoSQL, S3, un almacén de objetos, y Glacier, servicio de archivos de Amazon. Aunque todavía no está listo para el prime time, Amazon está ofreciendo a los clientes la oportunidad deregistrarse para obtener una vista previa limitadade Kinesis ahora.
Kinesis es relativamente tarde en la escena de flujo en tiempo real. Múltiples soluciones para hacer frente a grandes volúmenes de datos de streaming ya tienen algún punto de apoyo, incluyendo el de código abiertoTormentayS4 de Apacheproyectos, así como las ofertas comerciales, tales comoIBM InfoSphere Streams. Pero aunque todas estas soluciones pueden procesar enormes cantidades de datos de streaming, modelo organizado de Amazon es particularmente conveniente para las empresas que desean una solución de gestión y no les importa invertir en un trabajo de desarrollo, pero prefiere no invertir en cualquier infraestructura.
Leer 6 puntos restantesComentarios
     |
| Tweet |
No hay comentarios:
Publicar un comentario